
According to a report, the MLOps market size is projected to grow to $5.9 billion in the next few years. This is because machine learning has changed to business critical systems, driving real world decision making. However, many organizations still struggle to take models from the development stage into reliable production environments. That’s where MLOps can help.
MLOps guarantees the effective implementation of ML models throughout their lifecycles by bridging the gap between data science and IT operations. Just as crucial as creating models is making sure they function reliably and adjust to new inputs.
In this guide, we’ll discuss some MLOps best practices, from model deployment and monitoring to retraining and governance.
MLOps Lifecycle
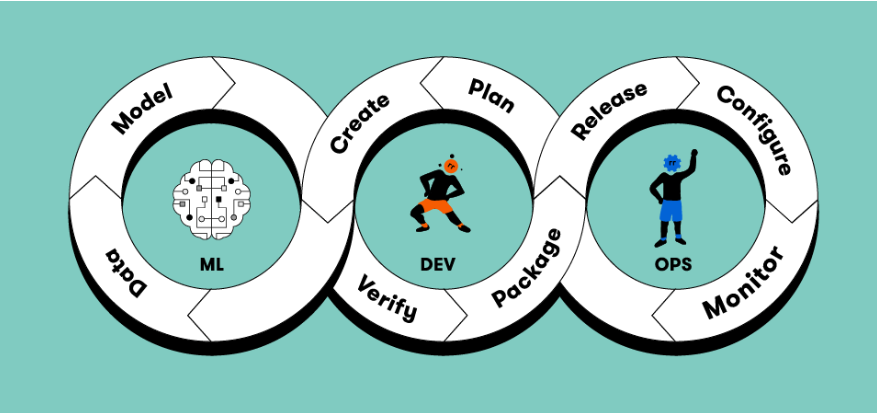
A systematic procedure for maintaining machine learning models from development to retirement is called the MLOps lifecycle. It emulates typical DevOps while incorporating machine learning-specific features like data management and model retraining.
There are multiple interrelated stages in the standard MLOps lifecycle.
- Data Collection
- Model Development and Training
- Model Evaluation and Validation
- Model Deployment
- Monitoring
- Retraining
Best Practices for Effective MLOps

Adopt a Collaborative Culture
Maintaining efficient processes requires teamwork. From the start of the model building process, data scientists and DevOps experts should collaborate. Silos may be avoided with a defined vision and objectives.
Additionally, promoting cross functional cooperation guarantees that models are in line with operational limitations and business goals.
Establish Version Control for Everything
Version control is necessary for data and model configuration in MLOps, just as it is for code in DevOps. Monitoring training scripts and dataset changes ensures reproducibility.
Managing experiment histories and dataset snapshots is made simple by programs like MLflow.
This approach helps data scientists identify what worked and why. This simplifies rollbacks when needed and ensures that any deployed model can be traced back to its origin.
Implement Continuous Integration and Delivery for ML
Machine learning model deployment and integration are automated using a dependable CI/CD pipeline. The pipeline can automatically initiate retraining when fresh data or better algorithms become available. This reduces manual errors. It also ensures that your ML systems always use the best performing model.
Ensure Data Quality
The performance of any machine learning model is significantly influenced by the quality of the training data. An element of successful MLOps is data validation.
Data pipelines should have automated validation checks to identify missing values or distribution changes prior to training. Also, setting up robust data governance practices ensures accountability and trust in your ML workflows. Additionally, maintaining documentation and metadata for datasets enables easier compliance.
Focus on Reusability
Reusable parts save time. Instead of beginning from scratch for every project, teams should create modular pipelines that can be adjusted for different use cases.
Containerization, which makes use of orchestration systems like Kubernetes, enables scalable deployments.
Moreover, reusable scripts improve operations and reduce setup times. It also promotes standardization across the organization.
Implement Model Validation
Just like software testing, machine learning models require thorough validation before deployment. This includes unit tests for code and performance evaluation on unseen test sets. In addition to accuracy, teams should test for robustness and bias. Monitoring metrics like model drift ensures the model’s reliability.
Prioritize Monitoring
MLOps doesn’t end with deployment; ongoing monitoring is required to ensure models operate correctly in production. By using observability frameworks, teams may monitor metrics like resource use and forecast accuracy.
Detecting anomalies or data drift early prevents performance degradation. Dashboards can provide real time insights into model health. This enables teams to react to possible problems in a proactive manner. Thus, integrating model measurements with business KPIs aids in measuring the model’s influence and coordinating its achievements with organizational objectives.
Automate
The foundation of MLOps is automation. Productivity and consistency can be increased by automating repetitive and error prone operations.
Tools like Kubeflow enable end to end automation. This frees teams to focus on innovation rather than manual maintenance.
However, automation should be implemented carefully. Humans should be kept in the loop for critical decision points like model approval or ethical review ensure oversight.
Incorporate Explainability
In modern AI systems, explainability is a necessity. MLOps frameworks should include tools and processes for understanding how models make decisions.
Model predictions can be interpreted with the use of methods such as LIME. In addition to fostering trust among stakeholders, this transparency is frequently necessary for regulatory compliance.
Establish Feedback Loops
Production data is a constant source of learning for efficient MLOps systems. Creating a feedback loop between deployment and development ensures models change as real world conditions change. Feedback mechanisms like user input or drift detection help identify when retraining is necessary.
What Tools and Technologies Power Modern MLOps?

Data Management and Version Control Tools
Every machine learning endeavor starts with data. Effective management is a key component of MLOps.
DVC
DVC extends Git capabilities to handle datasets and experiment tracking. It enables versioning of large data files. Hence, it ensures reproducibility.
LakeFS
LakeFS provides Git like operations on data lakes. Therefore, this allows teams to manage datasets with branches and commits. It also makes rolling back or testing new data versions much easier.
Apache Hudi
Big data systems benefit from Apache Hudi’s ACID transactions and versioning features, which guarantee data pipeline consistency.
Experiment Tracking and Model Management Tools
MLflow
MLflow is one of the most popular open source tools that helps track experiments and manage models across their lifecycle. It also offers model registry capabilities for deployment and governance.
Weights & Biases
It’s ideal for tracking experiments in real time. Also, W&B integrates with common ML frameworks like TensorFlow and PyTorch. It helps visualize training progress and collaborate with teams.
Neptune.ai
Neptune.ai is a lightweight experiment tracking tool that integrates seamlessly with development pipelines and provides flexible metadata storage for experiments and results.
Model Deployment and Serving Platforms
It might be difficult to deploy a model into production, particularly when it comes to latency or scalability. MLOps simplifies deployment through dedicated serving platforms.
TensorFlow Serving
A highly efficient system for serving TensorFlow models in production environments. It supports versioning and allows seamless updates without downtime.
TorchServe

TorchServe was created by Facebook and AWS with the goal of providing PyTorch models with scalability and simple API interaction.
KServe
A Kubernetes based solution, KServe automates deployment and management of ML models. It supports multiple frameworks including Scikit learn.
Seldon Core
An open source platform that allows large scale model deployment and monitoring on Kubernetes. It supports canary rollouts and explainability features.
BentoML

BentoML simplifies the packaging and deployment of ML models as APIs. It also enables flexible integration with web services.
Workflow Orchestration and Automation Tools
To manage the complexity of ML pipelines automation is crucial. Workflow orchestration tools ensure these steps run efficiently and consistently.
Apache Airflow
A reliable workflow orchestration tool widely used for scheduling and monitoring data pipelines. It makes it possible to define machine learning workflows as code and enhance traceability.
Kubeflow Pipelines
Kubeflow was created especially for machine learning. It enables you to create and keep an eye on whole machine learning processes on Kubernetes.
Model Monitoring
The battle is not over when a model is deployed. Real time performance monitoring guarantees that it keeps producing correct findings. Metrics tracking and performance degradation management are made easier with the use of MLOps observability technologies.
Evidently AI
An open source framework for monitoring data drift and statistical changes in production data.
Arize AI
Arize AI offer comprehensive model observability solutions with dashboards and explainability reports.
Grafna
Grafna is commonly used in DevOps monitoring tools that integrate well into MLOps pipelines to visualize model metrics and system health.
CI/CD Tools
Bringing DevOps best practices into machine learning requires CI/CD tools tailored for ML pipelines. These tools automate retraining and deployment, this enables continuous improvement.
Jenkins
Jenkins is a classic automation tool that can be adapted for ML pipelines to handle model builds and deployments.
Circle CI
It’s a Lightweight CI/CD tool with flexible integration options for training and deploying ML models.
Infrastructure and Containerization Tools

Containerization ensures that models run consistenly across environments. MLOps teams utilize container technologies to create isolated and scalable deployments.
Docker
The foundation of modern deployment, Docker packages models and dependencies into containers and ensure consistency across environments.
Kubernetes
It orchestrates containers at scale, enabling load balancing and rolling updates for ML services.
Helm
Helm simplifies Kubernetes deployments with templated configurations files. This makes it easier to manage complex ML infrastructure.
Terraform
As an Infrastructure as Code tool, Terraform helps automate the provisioning of compute and networking resources for MLOps pipelines.
Cloud Platforms and Managed MLOps Services
Cloud providers have developed specialized MLOps platforms that simplify the end to end lifecycle management of machine learning models.
AWS SageMaker
A completely managed package for data preparation and deployment is provided by AWS SageMaker. Analytics and AWS DevOps tools are easily integrated with it.
Azure Machine Learning
Azure supports automated ML and MLOps integration with Azure DevOps. Furthermore, it also ensure pipeline management.
Databricks MLflow

It combines the power of MLflow with Databricks’ data engineering capabilities. It creates a unified platform for analytics and model operations.
What Are Some Common MLOps Challenges?

Managing Data Complexity
Data is the heartbeat of every ML model, but it’s also one of the biggest pain points in MLOps. Data often originates from several sources and has many different formats. Furthermore, inconsistent data quality may lead to erroneous models. Another major challenge is data drift. It causes the model’s performance to degrade silently in production.
Scaling Infrastructure
It takes a lot of processing power to train and implement machine learning models, frequently requiring distributed systems or GPU clusters. The complexity of controlling infrastructure costs and performance increases as firms grow their ML programs.
For example, a model that functions well in a development setting could not perform well under production workloads or might need a lot of fine-tuning to maximize inference delay.
Lack of Standardization Across Teams
Collaboration and deployment become challenging when teams employ disparate tools and code standards. One team may utilize MLflow to monitor studies, while another may use spreadsheets; one data scientist may use PyTorch, while another may use TensorFlow.
It is almost hard to maintain version control and compliance without a defined MLOps procedure.
Monitoring Model Drift
Once a model is implemented, its performance might decline over time owing to changes in real world data, a process known as model drift. Drift can result in inaccurate data patterns if it is not addressed.
Unfortunately, many teams overlook post deployment monitoring, focusing more on model training than long term maintenance.
Automating Retraining
Many businesses find it difficult to close the loop between detection and action, even with excellent monitoring. Retraining is frequently done manually when model drift or performance decline is detected.
Ensuring Security
When machine learning models manage sensitive data in regulated industries like healthcare, security, and compliance becomes more difficult. Protecting data pipelines and model endpoints from hostile assaults is two of the difficulties.
Final Words
MLOps transforms machine learning from experimentation to reliable production. By combining automation and collaboration, teams can build scalable and high performing ML systems.



