
Hero Introduction
AI adoption is shifting from experimental pilots to production-grade systems embedded in core business workflows. For CTOs, the challenge is designing AI products that are reliable and maintainable under real-world constraints.
This guide breaks down the AI product development lifecycle into concrete and engineering-focused stages to help you build production-ready AI systems.
Executive Summary
AI product development is a non-deterministic and data-centric engineering discipline requiring tight integration between data pipelines and production infrastructure. Unlike traditional systems, AI products require continuous retraining and monitoring.
What Makes AI Product Development Different from Traditional Software?
At a systems level, product development introduces a paradigm shift from deterministic software engineering to probabilistic and data-driven system design. This impacts everything, including architecture and testing, to deployment and long-term maintenance.
Deterministic Logic vs Probabilistic Behavior
Traditional software operates on explicitly defined rules:
- Given input X, the system produces output Y
AI systems, however, approximate functions:
- Output is a probability distribution, not a fixed result
- Behavior depends on training data, feature representation, and model weights
Hence, this introduces:
- Non-deterministic outputs
- Variability across model versions
- The need for confidence thresholds instead of binary correctness
Therefore, you must design systems that tolerate uncertainty, using thresholds, fallback mechanisms, and human-in-the-loop workflows where necessary.
Data as a Core System Dependency
In traditional applications:
- Code defines behavior
- Data is typically transactional or user-generated
In AI systems:
- Data defines behavior
- Model performance is directly proportional to data quality and relevance
This makes data pipelines a first-class component:
- Data ingestion
- Data cleaning and normalization
- Feature extraction and transformation
Some of its key challenges are:
- Inconsistent or incomplete datasets
- Label noise in supervised learning
- Data leakage between training and validation sets
Hence, you aren’t just maintaining code, you are maintaining datasets and data lineage. Versioning data becomes as critical as versioning code.
Continuous Learning vs Static Releases
Primarily, traditional software follows a release cycle:
- DevelopTestDeployMaintain
AI systems require continuous retraining:
- Data evolvesModel DriftRetrainRedeploy
Thus, this introduces:
- Concept drift: Changing relationships in data
- Data drift: Shifting input distributions
Hence, you need automated retraining pipelines, scheduled or event-driven, integrated into your MLOps workflows.
Testing Becomes Statistical, Not Binary
In traditional QA:
- Test cases have executed outputs
- Pass/fail criteria are deterministic
In AI systems:
- Outputs are evaluated using statistical metrics
- No single correct answer exists
Testing layers in AI systems include:
- Unit testing: Data transformations, feature pipelines
- Model validation: Accuracy, precision, recall, F1
- System testing: Latency, throughput, scalability
- Business validation: Impact on KPIs
Training-Serving Skew and Environment Parity
A unique challenge in AI systems is training-serving skew:
- The model is trained on one data distribution
- It encounters a different distribution in production
Some of its common causes are:
- Inconsistent preprocessing logic
- Feature mismatches
- Time-based data differences
Its implications are:
- Use shared feature pipelines for training and inference
- Implement feature stores
- Ensure strict environment parity across development and production
Model Lifecycle Management
Some traditional software lifecycle focuses on:
- Source code versioning
- Build and deployment pipelines
AI systems introduce additional artifacts:
- Datasets
- Feature sets
- Model binaries
- Hyperparameters
Each must be:
- Versioned
- Trackable
- Reproducible
Some of its engineering implications are:
- Model registries
- Experiment tracking systems
- Data versioning tools
Infrastructure Complexity Increases Significantly
AI systems require specialized infrastructure beyond standard application stacks:
- GPU/TPU acceleration for training
- Distributed computing for large datasets
- Low-latency inference systems for real-time predictions
Typical AI Stack Includes:
- Data pipelines: Airflow, Spark
- Storage: Data lakes, warehouses
- Training frameworks: PyTorch, TensorFlow
- Serving layers: API gateways, model servers
You are managing a multi-layered system where data engineering, ML engineering, and backend systems must work in sync.
Observability Extends Beyond System Metrics
Furthermore, traditional observability focuses on:
- CPU, memory, latency
- Error rates
AI systems require additional monitoring:
- Input data distribution
- Prediction distribution
- Model confidence scores
- Drift detection metrics
Therefore, monitoring must include both:
- System health
- Model health
Explainability and Interpreability Requirements
Traditional systems are inherently explainable; you can trace the logic step by step.
AI models, especially deep learning systems, act as black boxes:
- Decisions are not easily interpretable
- Regulatory environments may require explainability
Its engineering implications are:
- Use interpretable models where required
- Implement explainability tools
- Maintain audit trails for decisions
Cross-Functional Collaboration is Mandatory
Traditional development teams are often siloed:
- Backend
- Frontend
- QA
AI systems require tight collaboration between:
- Data engineers
- ML engineers
- DevOps/MLOps engineers
- Domain experts
Its engineering implication are:
- Shared ownership of pipelines
- Integrated workflows
- Faster iteration cycles
The Complete AI Product Development Lifecycle
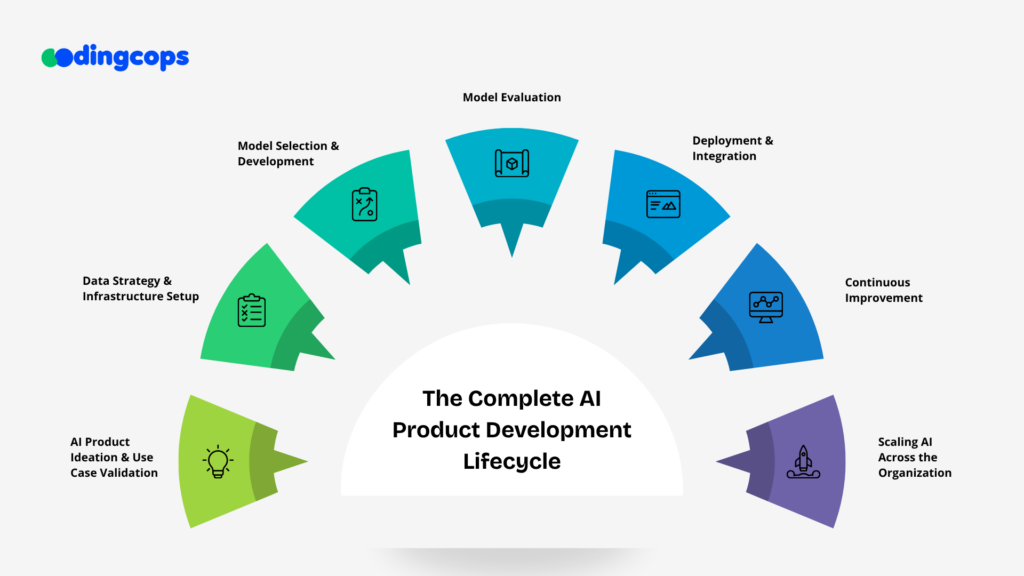
AI product development is not a linear engineering pipeline; it’s a continuous, feedback-driven system where data and production behavior constantly influence each other. For CTOs, success depends on building an end-to-end lifecycle that is reproducible and scalable across teams and infrastructure.
AI Product Ideation & Use Case Validation
AI projects often fail not because of poor models, but because of poorly defined problems. This stage ensures you are solving the right problem before any engineering begins.
At a technical level, ideation is about translating business requirements into machine learning problem types and validating whether the problem is even solvable with available data.
Map business problems to ML tasks:
- Classification: fraud detection, churn prediction
- Regression: forecasting, pricing models
- Ranking systems: search, recommendations
- NLP or generative AI use cases
Data Strategy & Infrastructure Setup
Data is the foundation of any AI system. Without a strong data architecture, even the best models will fail in production.
This stage focuses on building pipelines that ensure data is clean, versioned, and consistently available across training and inference environments.
Core Data Architecture Components
1. Ingestion Layer
- Batch processing: ETL pipelines using Airflow, Spark
- Real-time streaming: Kafka, Flink
2. Storage Layer
- Data lakes for raw and unstructured data
- Data warehouses for structured analytics
- Object storage for scalable persistence
3. Feature Layer
- Feature stores for reusable ML features
- Online/offline feature consistency management
Engineering Requirements
- Scheme validation and enforcement
- Data cleaning and normalization pipelines
- Deduplication and anomaly detection
- Data versioning for reproducibility
Governance & Security
- Role-based access control
- Encryption for data at rest and in transit
- Audit logs and compliance tracking
- Data lineage tracking across pipelines
Model Selection & Development
Once data pipelines are stable, the next step is selecting and building models that can learn meaningful patterns from that data.
This phase is highly experimental and requires structured iteration.
Model Selection Options
- Pre-trained foundation models
- Fine-tuned models
- Fully custom models
Core Development Workflow
- Feature engineering and selection
- Model architecture design
- Training on distributed systems
- Hyperparameter optimization
Experiment Management
You can track experiment management using MLflow. Moreover, you can log the following:
- Dataset versions
- Hyperparameters
- Model architecture
- Evaluation metrics
Model Versioning
- Store multiple model iterations in a registry
- Maintain reproducibility across environments
- Track lineage from datafeaturesmodel output
Model Evaluation
Model evaluation ensures that what works in training also works in real-world conditions. Unlike traditional software testing, AI evaluation is statistical and probabilistic in nature.
Advanced Validation Techniques
- Cross-validation for reliability
- Holdout validation sets
- Stress testing with edge-case data
- Adversarial testing for robustness
Fairness & Bias Checks
- Segment-wise performance evaluation
- Demographic parity analysis
- Bias detection in training datasets
Deployment & Integration
Deployment is where the most AI systems fail, not due to model quality, but due to engineering gaps between training and production.
This stage focuses on serving models reliably at scale.
Deployment Architectures
- Batch interference pipelines
- Real-time inference APIs
- Hybrid systems
Infrastructure Stack
- Docker for containerization
- Kubernetes for orchestration
- Model serving frameworks:
- TensorFlow Serving
- TorchServe
- FastAPI-based custom servers
MLOps Pipeline
- Continuous integration for ML pipelines
- Automated model testing before deployment
- Model registry integration
- Version-controlled deployments
Continuous Improvement
AI systems degrade over time due to changes in data and user behavior. This makes continuous improvement a core engineering requirement, not a post-launch activity.
Monitoring System Components
- Input data distribution tracking
- Prediction output distribution monitoring
- Real-time performance dashboards
- System latency and error tracking
Drift Detection
- Data drift
- Concept drit
- Use statistical methods:
- Population Stability Index
- Kolmogorov-Smirnov tests
Retraining Strategies
- Scheduled retraining
- Trigger-based retraining
Feedback Loops
- Capture user interactions
- Use labeled production data for retraining
- Automate feedback ingestion pipelines
Scaling AI Across the Organization
Once a single AI system is successful, the next challenge is scaling it across teams, products, and business units.
This requires both technical standardization and organizational alignment.
Platform Engineering Approach
You should build internal ML platforms like:
- Feature stores
- Model registries
- Experiment tracking systems
- Shared training pipelines
Standardization Practices
- Unified data pipelines
- Reusable features engineering modules
- Commom deployment templates
- Centralized monitoring systems
Infrastructure Scaling
- Distributed training systems
- GPU/TPU optimization strategies
- Cost-aware compute scheduling
- Auto-scaling inference services
Organizational Scaling
- Dedicated MLOps teams
- Data engineering teams aligned with ML teams
- Cross-functional AI product squads
- Governance and review frameworks
Best Practices for CTOs Leading AI Initiatives
Leading AI initiatives at the CTO level is less about selecting algorithms and more about designing systems and organizational structures that allow AI to succeed at scale. The biggest differentiator between successful and failed AI programs is not model quality, it’s execution discipline across data, engineering, and governance.
Start with Business-Aligned AI Use Cases
A common failure pattern is starting with technology exploration instead of business alignment. CTOs should enforce a strict rule: no model without a measurable business objective.
How to operationalize this?
Define AI use cases in terms of KPIs:
- Revenue uplift
- Cost reduction
- Operational efficiency
Moreover, you should translate vague ideas into ML problems. For example:
- Improve customer experience sentiment analysis + recommendation system
- Reduce fraudanomaly detection + classification models
Invest Early in Data Engineering and MLOps Infrastructure
AI success is heavily dependent on infrastructure maturity. Without strong data pipelines and MLOps practices, models cannot be reliably trained, deployed, or maintained.
- Invest in scalable data pipelines
- Implement features stores for reusable ML features
- Enforce strict schema validation and data contracts
- Ensure data versioning for reproducibility
Standardize the MLOps Lifecycle
Without MLOps, AI systems remain experimental and cannot scale reliably.
Important MLOps Practices
- CI/CD pipelines for ML models
- Automated training and validation workflows
- Model versioning and registry management
- Reproducible experiments with tracking tools
Design for Production
A common mistake is treating AI models as research artifacts instead of production systems.
Production-First Design Principles
- Assume models will degrade over time
- Optimize for latency and throughput
- Build fallback mechanisms for model failure
- Ensure training-serving parity
Infrastructure Considerations
- Containerized model deployment
- Orchestration via Kubernetes
- Scalable inference services
- Load balancing for high-traffic inference endpoints
Focus on Model Observability
Traditional software monitoring is not enough for AI systems. CTOs must implement model observability layers.
What to Monitor?
- Input data distributions
- Prediction distributions
- Model confidence scores
- Business KPIs tied to model output
Operational Practices
- Real-time dashboards for model health
- Automated alerts for performance degradation
- Logging of predictions for auditability
Optimize for Cost-Aware AI Infrastructure
AI workloads can become extremely expensive if not optimized properly.
Cost Optimization Strategies
- Use model distillation for large models
- Implement batching for inference requests
- Optimize GPU utilization for training workloads
- Choose between CPU vs GPU inference based on latency needs
Architecture Decisions
- Separate training and inference infrastructure
- Use autoscaling for inference endpoints
- Cache frequent predictions where possible
Manage Risk and Bias
AI systems introduce regulatory and ethical risks that must be managed at the architectural level.
Risk Areas
- Data privacy violations
- Model bias and unfair outcomes
- Lack of explainability in decisions
- Regulatory non-compliance
Mitigation Strategies
- Implement explainability tools
- Perform bias audits across datasets
- Maintain audit logs for model decisions
- Restrict sensitive feature usage where required
Align AI Metrics with Business Outcomes
Technical metrics alone don’t define success. Therefore, you as a CTO must ensure AI systems deliver measurable business impact.
Technical Metrics
- Accuracy, precision, and recall
- Latency and throughput
Business Metrics
- Revenue uplift
- Cost reduction
- Customer retention improvement
Final Words
AI product development demands more than models, it requires a structured, end-to-end lifecycle built on data and continuous iteration. CTOs who prioritize scalability and business alignment can turn AI from experimentation into a reliable, production-grade capability that drives measurable impact.



