
Hi folks, welcome to another interesting yet scholarly article related to machine learning. Today, we will discuss the top machine learning libraries that software engineers should use. Other than this, there is comprehensive information about what exactly machine learning libraries are and when one should use them. Moreover, things don’t end here, as we have also covered the importance of machine learning libraries that fill the remaining knowledge gaps.
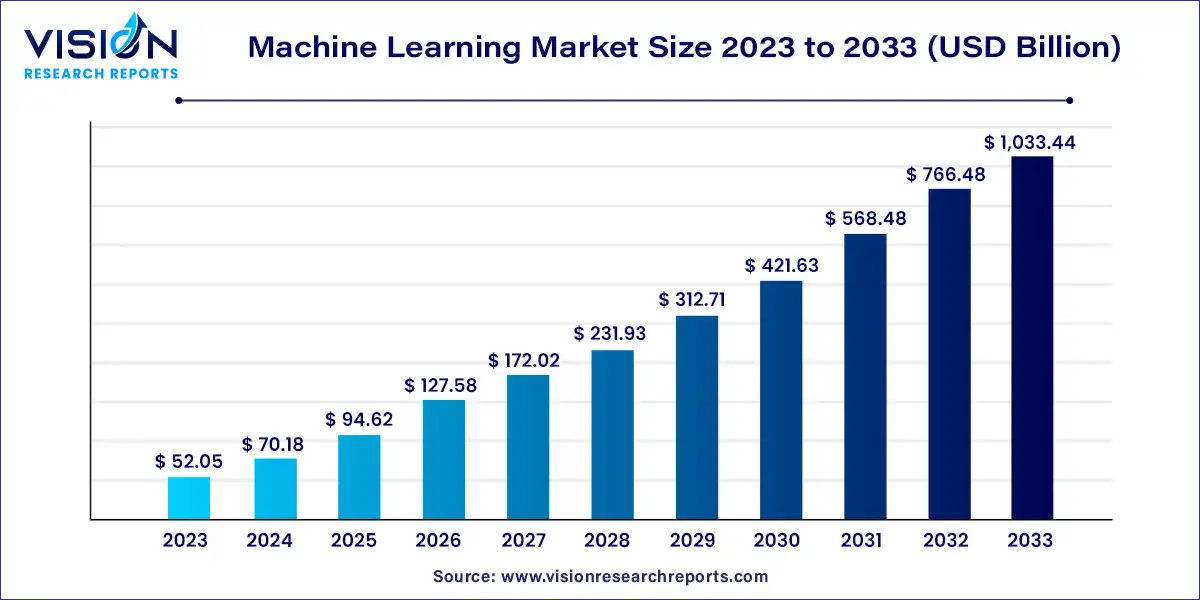
Before that, it is important to mention that we are in 2025, and according to Vision Research Reports, the market size of machine learning is $94.62 billion. The astonishing part is, these numbers are expected to reach $1033.4 billion by 2033. That’s mind-blowing!
Since machine learning is becoming an integral part of modern software applications, the use of its libraries and frameworks is also increasing. Hence, hiring well-versed and expert Machine Learning experts is the best decision one can make while building ML systems. Moreover, it is the need of the hour to address the audience about the best machine learning libraries that they should use in ML development.
So, this article explores the top machine learning libraries that every software engineer should know.
Let’s start!
What is a Machine Learning Library or Framework?
A machine learning library or framework is a collection of tools that assist software engineers, data scientists, and machine learning experts in building ML models without delving into the intricacies. Using such libraries and frameworks streamlines the development process, and programmers don’t have to reinvent the wheel for building specific ML applications.
ML libraries and frameworks support ML engineers by making the development process less intricate and more effortless.
Machine Learning Libraries – An Understanding
The machine learning libraries play a crucial role in developing ML models, AI systems, data science, deep learning, NLP, computer vision, and in all ML-related fields. These libraries come with pre-written code, algorithms, and tools that assist in developing and running ML models and data analysis tasks.
They provide a way for all the technical people to work with complex ML algorithms without having to develop from scratch.
Today, machines are dependent on effective models to learn progressively and work autonomously. As far as this is concerned, there are several ML libraries that come with unique capabilities to easily implement complex algorithms and test sophisticated models.
Key Elements of an ML Library

- Libraries have Various Algorithms
The machine learning libraries have various algorithms for developers to assist them in building projects. These may include classification, regression, and clustering algorithms.
- Tools for Model Performance
While working with ML, developers have to assess the performance of the ML models. For this, libraries include tools for assessing the performance of models with accuracy, precision, recall, and F1 score metrics.
- Data Preprocessing Features
Moreover, machine learning frameworks also offer data preprocessing features for data cleaning and data preparation. Data preprocessing is essential for machine learning models to work accurately.
- Data Visualization
Lastly, libraries allow developers and users to visualize data in the form of charts and graphs. This helps them identify patterns, trends, and outliers.
Importance of Machine Learning Libraries
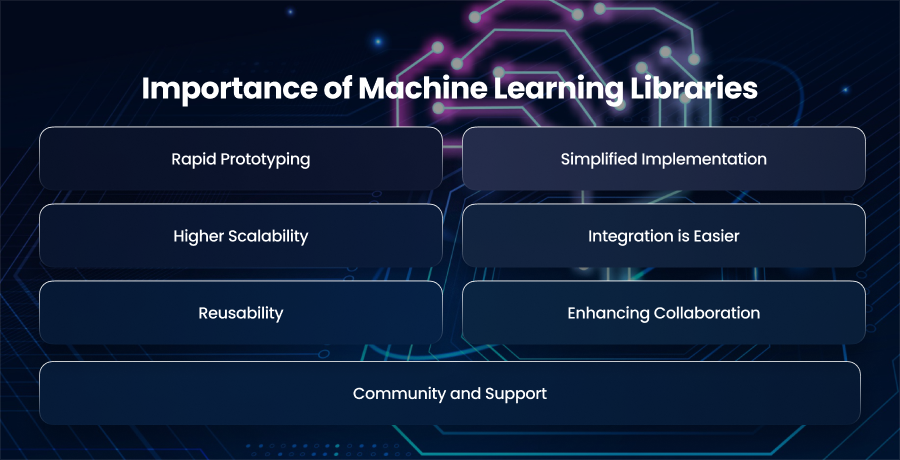
What more importance could ML libraries have than assisting developers with pre-built functions, training, and deploying machine learning models and algorithms to streamline the development? Let’s understand a little deeply how these libraries are empowering software engineers:
Rapid Prototyping
Firstly, developers can enjoy rapid prototyping by using ML frameworks and libraries. Engineers can build, test, and iterate on ML models quickly without diving into complexities every time.
Simplified Implementation
Secondly, these libraries promote simplified implementation of complex algorithms such as gradient descent, decision trees, or neural networks. It is because these frameworks come pre-packaged and optimized.
Higher Scalability
Further, scalability is easier using machine learning libraries because they support distributed computing, GPU acceleration, and production-level deployment.
Integration is Easier
Moreover, integrating with other tools is easier. Most libraries often work smoothly with data preprocessing and visualization tools and web frameworks.
Reusability
The machine learning libraries encourage reusability because of modular and reusable components. Moreover, this enhances efficiency as developers won’t have to rewrite code for various applications.
Enhancing Collaboration
Furthermore, these libraries play the role of a bridge between ML experts and developers by providing tools and methodologies. This not only enhances collaboration but ensures that the project follows the industry best practices.
Community and Support
Lastly, almost all ML libraries have a huge community and support. This means the active community and support are working for constant improvement and ample learning resources.
When to Use a Machine Learning Library?

There are certain scenarios where machine learning libraries play their part. Here is a list of points that tell you the instances where one should opt for a machine learning library or framework.
- Working with Large Datasets
You should opt for ML libraries when there is a need to deal with large datasets. In this scenario, using ML libraries can optimize performance and process huge amounts of data efficiently.
- Achieving Speed and Efficiency
When there is a need to achieve speed and efficiency simultaneously, you can use libraries instead of coding. This allows you to implement and test modules efficiently and quickly.
- Need for Pre-trained Models
ML libraries come into play when you need pre-trained models that are trained on massive datasets. You can fine-tune them for your task without any need for data or computing power.
- Integration of ML into Applications
Moreover, libraries provide APIs that allow easy integration into web frameworks, mobile applications, or cloud services. This makes the ML libraries ideal for real-world software integration.
- Facing a Problem
When you are in a problem such as pattern recognition, prediction, or decision making, you should use ML libraries.
Top Machine Learning Libraries for Software Engineers

Now, the time has come to dive into the core of our blog. In this section, you will learn about the best and top ML libraries that assist developers in machine learning.
Scikit-Learn
Scikit-learn is an ML library used for various tasks. It has comprehensive tools for building, evaluating, and deploying various models. It is built on NumPy, SciPy, and matplotlib, which makes it an ideal choice for data analysis and basic ML workflows.
Key Features of Scikit-Learn
- Preprocessing utilities
- Pipelines for model chaining and validation
- Regression, classification, clustering, and dimensionality reduction
TensorFlow
Developed by Google, it is another popular machine learning library that is ideal for research and enterprise-level application development. It is a highly scalable and flexible library that is also good for tasks like neural networks and natural language processing.
Key Features of TensorFlow
- TensorBoard for data visualization
- Runs on CPUs, GPUs, and TPUs
- Keras API for rapid prototyping
- Includes a wide range of pre-trained models and datasets
Keras
Keras is an open-source, deep learning library that integrates into TensorFlow for building and training neural networks. This integration boosts a user-friendly interface, and it becomes an ideal library for rapid prototyping.
Moreover, it is especially a good choice for beginner-level ML engineers working with neural networks.
Key Features of Keras
- It has a modular design
- Runs on CPU and GPU
- Easy debugging and testing
- Cross-platform compatibility
OpenCV
When there is a complex machine learning problem, OpenCV plays its part. It is a popular ML library that assists ML experts and researchers in handling complex computer vision tasks. It is widely used in artificial intelligence, robotics, and image analysis. Thus, using this library, one can process images and videos to identify faces, objects, and human handwriting.
Key Features of OpenCV
- Image recognition
- Motion tracking
- Facial recognition
PyTorch
PyTorch is yet another popular library of machine learning that is developed by Meta. PyTorch shines in academia and research because of its ease of use and dynamic computational graph. Further, programmers use PyTorch for a dynamic computation graph for debugging and modifying models in real-time.
Key Features of PyTorch
- Dynamic computation graph
- TorchVision and TorchText for domain-specific tasks
- Capable of running on GPUs for faster computation
- Strong community support
XGBoost
XGBoost is the short form of eXtreme Gradient Boosting, and it is a powerful library of machine learning with an ensemble learning method. This method is primarily used for structured or tabular data. It boosts high speed and performance compared to other tools.
Moreover, it shines where high accuracy and fast execution times are required, especially in predictive modeling tasks.
Key Features of XGBoost
- Regularization to reduce overfitting
- Parallel processing and GPU support
- Handles missing data internally
- Parallel processing to train models on large datasets
Hugging Face Transformers
The Hugging Face library stands as an outstanding machine learning platform that helps developers and data scientists construct and train, and deploy ML models. As an open-source library, Hugging Face maintains a broad selection of pre-trained machine learning models for natural language processing, computer vision, and various other domains.
Key Features of Hugging Face Transformers
- Comes with pre-trained models
- Highly versatile framework (supports PyTorch, TensorFlow, Jax)
- Open source and easy to use
Caffe
When you encounter deep learning tasks, Caffe plays its part with sheer speed, modularity, and expression. It is a popular framework for image classification and convulational neural networks. With Caffe’s highly optimized code and rapid deployment feature, machine learning developers can build deep learning applications involving computer vision quickly.
Key Features of Caffe
- High-speed processing
- Highly modular architecture
- Easy to use
- Supports image, vision, and speech recognition
H2O
H2O is another open-source, business-oriented ML library that supports implementing predictive analytics to make informed decisions based on granular data. It integrates with other programming languages and tools. It is commonly used in customer intelligence, analyzing insurance, advertising technology, etc.
Key Features of H2O
- It has superior algorithms that cover Random Forest, XGBoost, GBM, etc.
- Comes with an interactive GUI that requires no coding
- In-memory and distributed processing
Natural Language Toolkit
Lastly, we have NLTK, Natural Language Toolkit. It is a powerful, open-source ML library for dealing with natural language processing tasks. It has a vast range of tools and resources that are used to work with human language data. Moreover, it is used for text analysis, stemming, tokenization, parsing, and more.
Key Features of NLTK
- Stemming and lemmatization
- Parsing and sentiment analysis
- Text classification
Wrapping Up
To sum up, software engineers may create intelligent, scalable, and effective machine learning applications with the help of machine learning libraries and frameworks. The aforementioned libraries help developers by automating several processes, improving speed and performance, and pre-building code modules, regardless of the type of application.



